Nearly Optimal State Merklization
There's a meme going around Twitter that Solana is fast because it doesn't merklize its state.
I think I'm having a Eureka moment in performant blockchain design. Three main points:
— Larry Engineer (@larry0x) December 27, 2023
1. Do not Merklize chain state. This removes a huuuuge overhead in both execution and disk usage!
2. Use an SQL DB instead of a raw KV store. Instead of the chain implementing a query server,…
... And to some extent, this is true. In the Sovereign SDK, for example, we find that our (mostly unoptimized) merkle tree update currently takes at least 50% of our total runtime. Although exact performance numbers vary, updating the state trie is also a significant bottleneck for Ethereum and Cosmos node implementations.
The commonly cited reason for this inefficiency is that maintaining a merkle tree incurs lots of random disk accesses. And indeed, if you look at existing merkle tree implementations, you'll find this to be exactly the case. But I think this state of affairs is more an artifact of history than a fundamental limitation of merklization. In this post, I'll outline a more efficient strategy for merklizing state data, which I hope will be useful to the broader community.
N.B. Although this post makes some original contributions, it also combines many existing optimizations into a single scheme. When ideas were not developed originally, I credit the original author in block like this one.
Background: Why is Merklization Expensive?
A Very Brief Introduction To Addressable Merkle Trees
N.B. If you're totally unfamiliar with merkle trees and want a better introduction, I recommend the Jellyfish Merkle Tree paper
Addressable merkle trees usually work by grouping intermediate hashes into sets of 16 (called a node) and storing them in a key-value store like LMDB or RocksDB, where the key is the node hash and the value is the node itself.
To traverse the trie, implementations do something like the following:
struct ChildInfo {
is_leaf: bool,
hash: H256,
// ... some metadata omitted here
}
struct Node {
children: [Option<ChildInfo>; 16]
}
fn get(db: TrieDb, path: &[u4]) -> Option<Leaf> {
let mut current_node: Node = db.get_root_node();
for nibble in path {
let child: ChildInfo = current_node[nibble]?;
if child.is_leaf {
// Some checks omitted here
return db.get_leaf(child.hash)
}
current_node = db.get_node(child.hash)
}
}
As you can clearly see, this algorithm requires one random disk access for each layer of the tree that needs to be traversed. A basic property of addressable merkle tries is that their expected depth is logarithmic in the number of items stored, and the base of the logarithm is the width of the intermediate nodes. So if your blockchain has five billion objects in state and uses intermediate nodes with a width of 16, each state update will need to traverse to an expected depth of log_16(5,000,000,000) ~= 8. Putting all of this together, we can see that traversing a naive merkle trie will require roughly 8 sequential database queries per entry.
Compare that to the single query required to look up a value a "flat" (non-merklized) store like the one used in Solana, and you'll begin to see why merklization has such a big performance impact.
But Wait, there's More (Overhead)!
Unfortunately, this isn't the end of the story. In the previous discussion, we treated the underlying key-value store as if it could store and fetch values with no overhead. In the real world, though, lookups can be expensive. Almost all key-value stores use a tree structure of their own internally, which causes "read amplification" - multiplying the number of disk accesses for a random read by another factor of log(n).
So, for those of you keeping track at home, each read against a merkle tree incurs an overhead of log(n) ^ 2, where n is the number of items in global state. On Ethereum mainnet today, this log-squared factor is roughly 50 - meaning that each state update takes roughly 50 sequential disk accesses. When you observe that a typical Swap on Uniswap might write to 7 storage slots across 4 different contracts addresses and update the balances of 3 additional accounts, you can see how this becomes an issue.
This is the reason Ethereum doesn't just "raise the gas limit". Even though all the major full node implementations could easily a handle an order of magnitude increase in throughput today, the resulting state growth would eventually degrade node performance to an unacceptable degree.
Part 2: Let's make it better
But hang on... aren't merkle trees a theoretically optimal data structure? They should be fast! Can we make them live up to the hype?
I think so, yes. Here's how.
Step 1: Make the Trie Binary
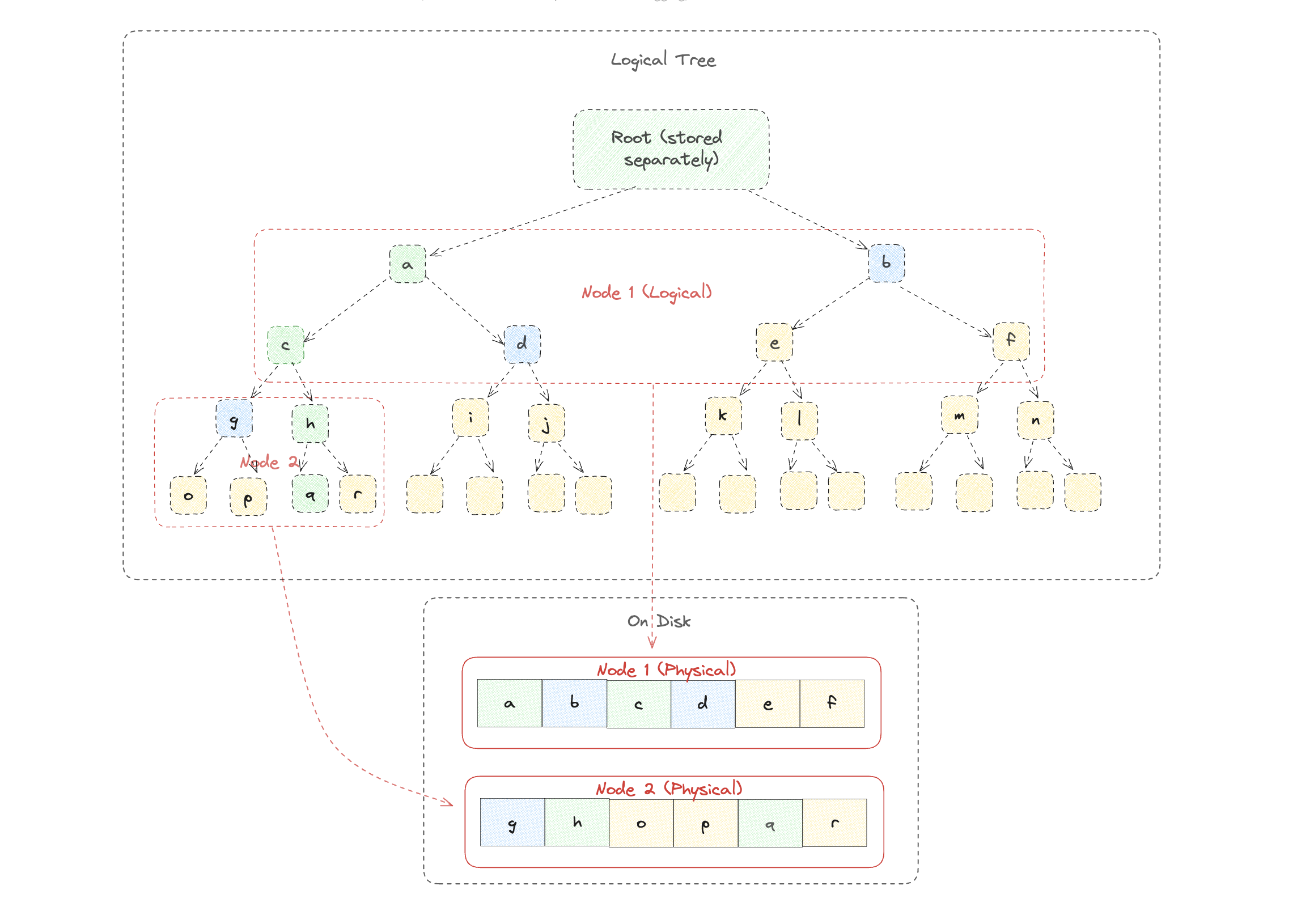
The first thing to do is to decouple your data storage format from the logical structure of your merkle trie. While it's a good idea to store nodes into groups of 16 (or more!) on disk and in-memory, using a high-arity merkle tree wastes computation and bandwidth. The solution is simple. Store your nodes in power-of-two-minus-two sized groups where each cluster contains a rootless binary subtree of some constant depth. In plain english, store your nodes as arrays of size (say), 6, where the array represents a binary tree with depth (say) 2 - with the additional wrinkle that the root of each tree is stored at the layer above. (See diagram).

The reason we store data this way is to ensure that all of the siblings needed in order to make a proof for a particular leaf are stored in the same nodes as the hashes that will be modified. If we also included the root of the binary trie in the node, then we would have to do an extra disk access each time we wanted to do an update that touched the root hash of a node (since the sibling of the root would be stored is stored in a different node).
Using this binary layout, we can eliminate a significant amount of overhead. For example, when we want to prove an insertion at q, we only need to perform four hash compressions: H(a || b), H(c || d), H(g || h), and H(q || r). This is significantly better than the number of compressions we would need to ingest a branch node in a 16-ary trie (roughly 9). Similarly, we only need to send four siblings in the merkle proof instead of the (minimum) 15 required by a 16-ary trie.
N.B. The idea of separating disk-format from tree arity is not new to Sovereign. It is already implemented in the Jellyfish Merkle Tree pioneered by Diem, and was suggested by Vitalik as least as early as 2018
Step 2: Improve the Disk Layout
Now that we've decoupled our on-disk layout from the underlying logical structure of the merkle tree, lets design the best possible layout.
N.B. Both Monad and Avalanche are doing related work at the same time this blog post is being written. Monad's work is still closed source, so it's not possible to assess how much overlap there is between our construction and theirs. Avalanche has open-sourced their FirewoodDB, but has not released much documentation, so I haven't yet had time to assess it in detail.
First, we're going to increase the size of our on-disk nodes to be the size of a page on a standard SSD. SSDs can’t read or write data in units smaller than a page - so storing smaller chunks than that just wastes IOPS. While there's some variance in the page size across popular SSDs, 4096 bytes seems to be a popular one. Let's start there.
Using nodes of size 4096, we can fit a rootless binary trie of depth 6 into a single node and still have 64 bytes left over for metadata. Great.
Now, how can we use our disk most effectively? Well, SSDs accesses have pretty high latency, but modern drives have lots of internal parallelism. So, we want to make sure that our lookups can be pipelined. In other words, the on-disk storage location where we keep a node should not depend on the specific contents of the merkle tree! That way, we can fetch all of the data at once, instead of reading one node at a time.
How can we pull that off? Simple - we give each node in our tree a unique key. Since we're using nodes of size 2^6 to store a binary tree of (logical) size 2^256, we have 2^250 distinct logical nodes that might be stored on disk. We'll give the root node the ID 0, its leftmost child the ID 1, and so on. To convert between the path to a node and that node's ID, we can use a relatively simple formula. The ith child of a the node with ID k has ID k * 2^6 + i.
Cool, now each node in our tree has a unique key. Using those keys, we can build a simple hashmap backed by our SSD. First, we pick some fixed number of blocks on the SSD to use for storing merkle tree nodes. Then, we assign each of those blocks a logical index. To compute the expected location of a particular node on disk, we simply use the formula index = hash(node_id) % num_blocks. In other words, it works exactly like a standard hashmap, just on disk instead of in memory.
The beauty of this construction is that it lets us look up all of the data on the path to a given node concurrently. Say, I want to update the merkle leaf at path 0x0f73f0ff947861b4af10ff94e2bdecc060a185915e6839ba3ebb86b6b2644d2f. I can compute exactly which pages of the SSD are likely to contain relevant merkle nodes up front, and then have the SSD fetch all of those pages in parallel. In particular, I know that my tree is unlikely to store more than a few trillion items, so in general I shouldn't find any non-empty nodes beyond the first ~40 layers of the tree. So, I can just fetch the first 40/6 = 7 nodes along the path - well within the capability of the SSD to handle in parallel.
But wait... hash maps can have collisions. How can we handle those? In the current setup, we can't. We can't even detect them. Thankfully, there's a simple fix that's been used in hash maps since time immemorial. If you're worried about collisions, just store the key inside the hash bucket alongside the value. By a lucky coincidence, our keys are just node ids - which themselves are just 250-bit integers. And as we mentioned before, each of our on-disk nodes happens to have 64 bytes of extra space. So, we can just follow the standard practice of storing the key along with its value and call it a day. With that setup in place, we can now detect collisions - so all that's left to do is figure out how to handle them. Since we still have about 32 bytes of extra space for metadata (which we can use to record the fact that a collision has occurred and link to the colliding node), this should be straightforward. There are a plethora of strategies in the literature (linear probing, quadratic probing, double-hashing, etc.), and a full discussion is out of scope for this article.
Whew, that was a lot. Let's take a moment and survey what we've built so far.
- We have a binary merkle-patricia tree, which gives us optimal hashing load and bandwidth consumption. This gives us performance which should be roughly equivalent to the best known constructions in terms of CPU, bandwidth, and (if we're using zk) proving cost.
- We have an on-disk structure which is mostly data independent. This means that in most cases we can fetch all nodes on the path to a particular leaf node with a single roundtrip to our SSD - taking full advantage of the drive's internal parallelism. Compare this to the naive merkle-tree construction I outlined in the first section, which needs 7 or 8 sequential database lookups, and about 50 sequential disk accesses due to nested tree structure.
Step 3: Compress your Metadata
At this stage, astute readers will have noticed a problem. up to this point, we've made two contradictory assumptions:
Assumption 1: Every item we want to store is only 32 bytes long
Assumption 2: Operations are logarithmic in the number of items actually stored in the tree, rather than in the logical size of the tree.
These two assumptions can't co-exist naturally. For Assumption 2 to hold, we need to use an optimized leaf-node construction which allows us to elide empty branches of the tree (see the JMT paper for details). To make that work, we need to give leaf nodes a completely different structure from internal nodes. So we need a domain separator to allow us to distinguish between internal and leaf nodes. (N.B. Domain separators are a good idea for security reasons as well. Type confusion is bad!) But, we've already stipulated that each of the items in the tree is a 32-byte hash. If we increase the size to 33 bytes, our on-disk nodes will get too large to fit on a single SSD page, killing our performance.
Thankfully, there's a simple solution here too. Since all we need is a single bit of discriminant, we just borrow the one bit from our hash. In other words, we mandate that all internal nodes must have the leading bit set to 1, and all leaf nodes must have their leading bit set to 0. (That leaves us with 255 bits of hash output, which still leaves plenty of security margin.)
Step 4: Halve your Compressions
Thanks to our trick from the previous section, we can now guarantee the invariant that every internal node is the hash of exactly two children, and that each child has a width of exactly 32 bytes. That means that at each layer of the tree, we need our hasher to ingest exactly 64 bytes of data. By a shocking coincidence, 64 bytes happens to be exactly the amount of data that can be ingested by many hash "compression functions" in a single invocation. (Most notably, SHA-256).
Unfortunately, such fixed-length compression functions are insecure on their own due to length extension attacks - so they aren't exposed by common cryptographic libraries. If you invoke the sha256() function in your favorite programming language, the library will be secretly padding your input with 64 bytes of metadata to prevent exactly this issue. Such padding is mandated by the NIST standard, and is absolutely necessary to ensure collision resistance in the presence of arbitrary-length messages.
But in our case, the messages don't have arbitrary length. Internal nodes are always constructed from 64 byte inputs. And thanks to our domain separators, we can easily distinguish internal nodes (which have fixed-size inputs) from leaf-nodes (which do not). By exposing the internals of our favorite hashing library, we can reduce the number of hashes required for tree traversal by a factor of 2 by using a padding-free hasher for internal nodes.
(Note: Messing with hash functions should only be done with good reason, and always under the supervision of a qualified cryptographer! This optimization is most useful in contexts where you're proving statements about the tree in zero-knowledge. If you're only using the tree in "native" contexts, you may want to skip this one!)
Step 5: Blake is cool. Be like Blake.
So far, we’ve focused exclusively on internal nodes of the tree. Now, lets turn our attention to leaf nodes.
The first thing to do is to recognize that, despite all of our hard work, state trees are expensive. While we've drastically reduced overheads, the cost for each access is still logarithmic in the number of values stored. "Normal" hashing, on the other hand, is relatively cheap. You can do a standard (linear) hash of about a kilobyte of data for the same compute cost as a single merkle tree lookup (assuming a tree depth of 32). So, if two values have even a relatively small chance off being accessed together, you want to store them in a single leaf.
But increasing leaf sizes hits an efficiency ceiling disappointingly quickly. Using a linear hasher like sha256, you pay roughly one compression for every 32 bytes of data - so the "breakeven" leaf size is about one kilobyte. (In other words, if you'd need to add more than a kilobyte of data to the leaf before you'd expect that two distinct values from that leaf would be acessed together, then the clustering would not be worthwhile.)
Thankfully, there's yet another trick we can use to reduce the overhead. @fd_ripatel recently pointed out to me that Blake3 uses an internal merkle tree instead of a linear hasher. This means that it's possible to do partial reads and incremental updates against a Blake3 hash with only logarithmic overhead. With this advancement, the breakeven size of a leaf increases from about a kilobyte to over a gigabyte. In other words, if you're using Blake3 as your leaf hasher then your leaves should be really, really big.
Note: It seems like it should be possible to combine the padding scheme from Blake3 with the compression function from just about any secure hasher to yield an optimized leaf hasher. But IANAC! If you are a cryptographer and have thoughts on this, please reach out!
Step 6: Cache Aggressively
Last but not least, if we're going to make a performant merkle tree we need to cache aggressively. We'll start simple - the (physical) root node of the tree should always live in memory. Why? Because any read or write against the tree is going to read and/or write that node. By keeping this node in memory, we can already reduce our expected SSD load from 7 pages per query to 6 pages per query.
But we can go further. If we keep the next level of the physical tree in memory, we can eliminate one more page from each query. This only costs us an extra 256k of memory (since there are 2^6 nodes of 4k each at this height), and we've already reduced our disk IOPS by 30%.
Step 7: Be Lazy
Last but not least, we can improve our efficiency even using pretty standard tricks.
First, we should avoid reading from the merkle tree wherever possible. We can do this by storing our leaf-data in a "flat" key-value store so that we don't need to traverse the tree just to read data. This reduces disk IOPS and reduces tail latencies (since each page we avoid querying is one less opportunity for a hash collision). If the data is modified, we'll still end up needing to read the merkle path eventually - but this optimization is still well worth the effort since reads are so common.
N.B. Almost all merkle tree implementations already supporting reading data from a flat store without traversing the trie.
Second, we should always defer updates to our trie for as long as possible. The obvious reason for this is that two sequential updates might both update the same key (meaning that we can skip one trie update altogether). The less obvious reason is that a properly implemented merkle tree is asymptotically more efficient when updates are done in large batches.
The reason for this is relatively easy to understand. Suppose we have a sequence of four writes against the pictured merkle tree. Since the tree has depth 4 (excluding the root), we incur a cost of 16 hashes if we perform the updates sequentially (4 hashes per update time 4 updates). But if we perform the updates in a batch, we only need 9 hashes to compute the new root. Intuitively, this is because the hashing work for the top layers of the tree is amortized across 4 inserts. Even though we made four modifications, we only recomputed the root hash once.

Conclusion
Using the techniques described in this post, it should be possible to reduce the disk-induced latency of merkle tree operations a factor of ten or more, the computational overhead by a factor of two or more, and the total disk IOPS by a factor of 25 or more. With those improvements, it’s my hope that the cost of generating state commitments should no longer be prohibitive even for high throughput chains.
Of course, this approach is not magic. In engineering, tradeoffs abound. In this case, we achieve much of our IO performance gains by sacrificing the ability to store a complete archive of the merkle tree at all points in time. Also, we require lower-level interfaces to the SSD than standard constructions - which translates to some engineering complexity. Still, we’re excited to see where this approach leads!
Acknowledgements
Thanks to…
- Cem Ozer and Patrick O'Grady for reviewing drafts of this post.
- Zhenhuan Gao, Yuxuan Hu, and Qinfan Wu for the Jellyfish Merkle Tree paper
- Peter Szilagyi for his excellent talk on the physical limits of Ethereum (and for his tireless work on Geth)
- Richard Patel and @dubbel06 for introducing me to Blake3’s secret merkle hasher
- Emmanuel Goossaert for his excellent series on SSDs.
Final Note
Since this post is now approaching Jon Charb levels of verbosity, I’ve made the editorial decision to omit a complete description of insertion, deletion, and proving algorithms compatible with the general construction described here. You can find suitable algorithms in the Jellyfish Merkle Tree repo that Sovereign co-maintains. To understand the batched algorithms, see the Aptos fork of the JMT. I’ve also omitted some details related to crash recovery, but the problem is not too difficult (hint: use a WAL). Finally, I’ve left aside the question of storage for the leaf nodes of the merkle tree. The best store for that data will depend on the application, but either a key-value store or a custom database might be appropriate.